Hadoop là gì? Tổng quan và vai trò trong Big Data
24/01/2026

Trong kỷ nguyên kinh tế số, dữ liệu được ví như “dầu mỏ” mới của mọi doanh nghiệp. Tuy nhiên, thách thức lớn nhất không nằm ở việc thu thập mà là làm thế nào để lưu trữ và xử lý hàng petabyte dữ liệu không cấu trúc một cách hiệu quả. Đây chính là lý do khiến khái niệm Hadoop là gì trở thành một trong những cột trụ quan trọng nhất trong giới công nghệ thông tin. Tại Trường Đại học VinUni, sinh viên ngành Khoa học máy tính luôn được trang bị kiến thức về các hệ thống phân tán như Hadoop để giải quyết các bài toán dữ liệu lớn toàn cầu.
Vậy cụ thể Apache Hadoop là gì và kiến trúc của nó có gì đặc biệt? Bài viết này sẽ phân tích chi tiết từ khái niệm đến cách thức vận hành thực tế của nền tảng này.
Để hiểu rõ Hadoop là gì, trước hết cần biết đây là một khung phần mềm (framework) nguồn mở được viết bằng Java, thuộc quản lý của Apache Software Foundation. Apache Hadoop là gì? Đó là một hệ sinh thái cho phép lưu trữ và xử lý các tập dữ liệu cực lớn (Big Data) theo mô hình tính toán phân tán. Thay vì cố gắng nâng cấp một siêu máy tính đắt đỏ, Hadoop kết nối hàng ngàn máy tính thông thường (commodity hardware) lại với nhau để tạo ra sức mạnh tổng hợp.
Hadoop đóng vai trò không thể thay thế nhờ các đặc tính ưu việt:

Hadoop là gì? Vì sao Hadoop quan trọng trong xử lý dữ liệu lớn?
Việc nắm vững ứng dụng của Hadoop là gì giúp doanh nghiệp và các nhà phát triển tối ưu hóa quy trình khai thác giá trị từ dữ liệu.
– Lưu trữ dữ liệu khổng lồ
Hadoop giải quyết bài toán “Data Swamp” (đầm lầy dữ liệu) bằng cách cung cấp một kho chứa tập trung (Data Lake) cho mọi loại dữ liệu: có cấu trúc, bán cấu trúc và không cấu trúc. Với cơ chế lưu trữ phân tán, Hadoop có thể quản lý hàng Petabyte (PB) dữ liệu mà các hệ thống truyền thống thường bị quá tải.
– Xử lý dữ liệu phân tán
Sức mạnh thực sự của Apache Hadoop là gì nằm ở khả năng xử lý song song. Thay vì xử lý dữ liệu tập trung tại một chỗ, Hadoop chia nhỏ công việc và gửi đến nơi dữ liệu đang nằm (Data Locality). Điều này giúp rút ngắn thời gian xử lý từ vài ngày xuống còn vài phút.
– Phân tích log (lịch sử ghi chép) và dữ liệu hành vi người dùng
Mọi lượt nhấp chuột, thời gian dừng trên trang hay lộ trình di chuyển của người dùng trên website đều tạo ra tệp log khổng lồ. Hadoop cho phép phân tích các tệp này để thấu hiểu hành vi khách hàng, từ đó giúp doanh nghiệp cải thiện giao diện và tăng tính cá nhân hóa.
– Ứng dụng trong Tài chính, Thương mại điện tử, AI và IoT

Ứng dụng thực tế của Hadoop trong doanh nghiệp.
Hệ sinh thái Hadoop được xây dựng dựa trên sự phối hợp chặt chẽ của 4 thành phần chính, tạo nên một bộ khung hoàn chỉnh từ khâu quản lý tài nguyên đến lưu trữ và xử lý. Sự phân tách rõ ràng giữa các lớp chức năng này không chỉ giúp hệ thống vận hành ổn định mà còn cho phép các nhà phát triển linh hoạt tối ưu hóa từng giai đoạn tùy theo quy mô dữ liệu thực tế.
HDFS là lớp lưu trữ. Nó chia nhỏ tệp dữ liệu thành các khối (blocks) và phân phối chúng trên các cụm máy tính. HDFS đảm bảo dữ liệu luôn sẵn sàng ngay cả khi một phần cứng bị hỏng.
MapReduce là mô hình lập trình xử lý dữ liệu. Giai đoạn Map thực hiện lọc và phân loại dữ liệu, trong khi giai đoạn Reduce tổng hợp các kết quả trung gian để đưa ra báo cáo cuối cùng.
Nhiều sinh viên thường hỏi Hadoop YARN là gì? YARN (Yet Another Resource Negotiator) là “bộ não” quản lý tài nguyên của hệ thống. Nó chịu trách nhiệm phân bổ CPU, RAM cho các tác vụ và lập lịch chạy ứng dụng trên toàn cụm.
Đây là tập hợp các thư viện và tiện ích Java cần thiết để các module khác khởi chạy và kết nối với nhau một cách đồng bộ.
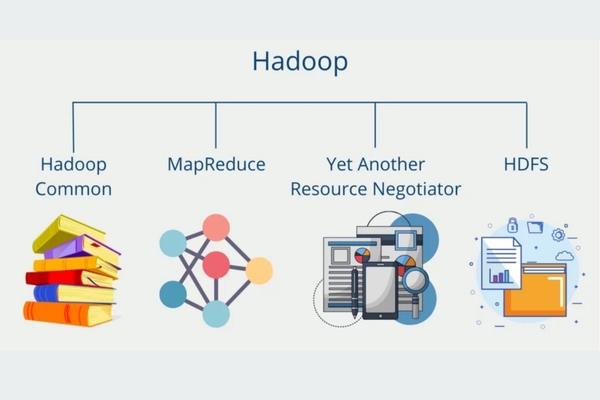
Kiến trúc và các thành phần chính của Hadoop.
Để giải quyết các bài toán dữ liệu khổng lồ mà những hệ thống đơn lẻ không thể xử lý, cơ chế vận hành của Apache Hadoop là gì? Hệ thống này hoạt động dựa trên triết lý “mang tính toán đến nơi lưu trữ dữ liệu” (Data Locality) thay vì di chuyển dữ liệu đến nơi tính toán. Quy trình này được tối ưu hóa qua 3 giai đoạn chiến lược:
Sự phối hợp nhịp nhàng giữa các thành phần giúp Hadoop xử lý hàng Petabyte dữ liệu một cách ổn định.
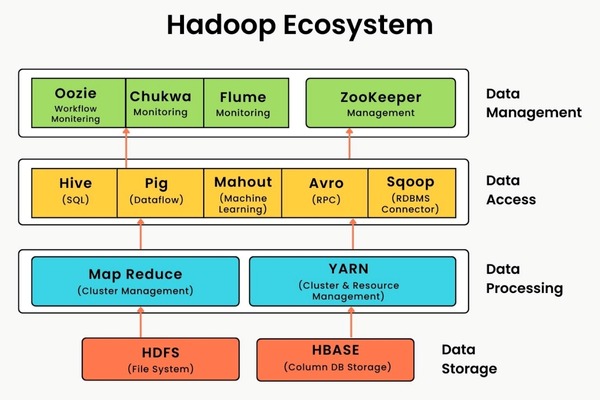
Các thức hoạt động của hệ thống Hadoop.
Việc làm chủ công nghệ xử lý dữ liệu lớn như Hadoop là gì là một phần quan trọng trong chương trình đào tạo tại Trường Đại học VinUni. Viện Kỹ thuật và Khoa học máy tính VinUni cung cấp chương trình Cử nhân Khoa học Máy tính theo chuẩn quốc tế, giúp sinh viên không chỉ nắm vững lý thuyết mà còn thực hành trực tiếp trên các hệ thống tính toán hiệu năng cao.
Đặc biệt, chương trình đào tạo tại VinUni được xác thực chất lượng bởi Trường Đại học Cornell và được xây dựng là bởi Viện Kinh doanh SC Johnson, giúp sinh viên có tư duy quản trị dự án công nghệ xuất sắc. Nếu bạn khao khát dấn thân vào con đường bắt đầu hành trình nghiên cứu chuyên sâu, hãy tìm hiểu về các lộ trình nghiên cứu sinh là gì tại VinUni để cùng các giáo sư tinh hoa kiến tạo những đột phá mới trong AI và Big Data.
Nếu bạn khao khát trở thành chuyên gia dữ liệu, hãy nghiên cứu chương trình Cử nhân Khoa học Máy tính tại Trường Đại học VinUni. Chương trình đào tạo được thiết kế nhằm khai phá tư duy nghiên cứu độc lập, đồng thời mở ra định hướng công nghệ mang tầm vóc quốc tế cho người học. Đây chính là bệ phóng vững chắc giúp bạn tự tin làm chủ những công nghệ phức tạp như Hadoop và sẵn sàng chinh phục các vị trí quan trọng trong những tập đoàn công nghệ hàng đầu thế giới.

VinUni là nơi chắp cánh cho những tài năng công nghệ làm chủ Hadoop.
Nghiên cứu thông tin chi tiết về tuyển sinh tại VinUni ngay hôm nay để củng cố nền tảng kiến thức khoa học máy tính, sẵn sàng cho những bước tiến đột phá trong sự nghiệp của bạn.









![Chính sách phát triển năng lượng mặt trời mái nhà [Cập nhật 2026]](https://vinuni.edu.vn/wp-content/uploads/2026/02/chinh-sach-phat-trien-nang-luong-mat-troi-1.jpg)
